In August, at a Quantified Self meeting in San Jose, I told how butter apparently improved my brain function. When I started eating a half-stick of butter every day, I suddenly got faster at arithmetic. During the question period, Greg Biggers of genomera.com proposed a study to see if what I’d found was true for other people.
Eri Gentry, also of genomera.com, organized an experiment to measure the effect of butter and coconut oil on arithmetic speed. Forty-five people signed up. The experiment lasted three weeks (October 23-November 12). On each day of the experiment, the participants took an online arithmetic test that resembled mine.
The participants were randomly assigned to one of three groups: Butter, Coconut Oil, or Neither. The three weeks were divided into three one-week phases. During Phase 1 (baseline), the participants ate normally. During Phase 2 (treatment), the Butter participants added 4 tablespoons of butter (half a stick of butter) each day to their usual diet. The Coconut-Oil participants added 4 tablespoons of coconut oil each day to their usual diet. The Neither participants continued to eat normally. During Phase 3 (baseline), all participants ate normally.
After the experiment was finished. Eri reduced the data set to participants who had done at least 10 days of testing. Then she made the data available. I wanted to compute difference scores (Phase 2 MINUS average of Phases 1 and 3) so I eliminated someone who had no Phase 3 data. I also eliminated four days where the treatment was wrong (e.g., in the sequence N N N N N B B N N B, where N = Neither and B = Butter, I eliminated the final Butter day). That left 27 participants and a total of 443 days of data.
Because the scores on individual problems were close to symmetric on a log scale, I worked with log solution times. I computed a mean for each day for each participant and then a mean for each phase for each participant.
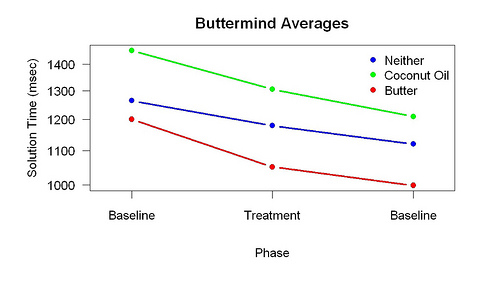 This figure shows the means for each phase and group. The downward slopes show the effect of practice. The separation between the lines shows that individual differences are large. (There was no reliable difference between the three groups during Phase 1.)
This figure shows the means for each phase and group. The downward slopes show the effect of practice. The separation between the lines shows that individual differences are large. (There was no reliable difference between the three groups during Phase 1.)
The point of the baseline/treatment/baseline design is allow for a large practice effect and large individual differences. It allows a treatment effect to be computed for each participant by computing a difference score: Phase 2 MINUS average of Phases 1 and 3. The average of Phases 1 and 3 estimates what the results would be if the treatment made no difference.
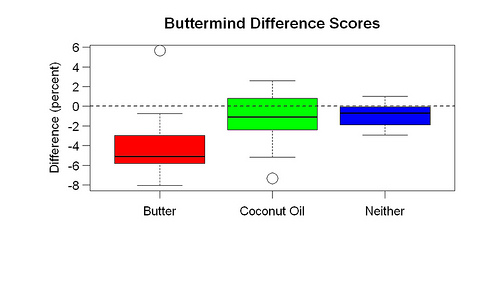
This graph shows the difference scores. There are clear differences by group. A Wilcoxon test comparing the Butter and Neither groups gives one-tailed p = 0.006.
The results support my idea that butter improves brain function. They also suggest that coconut oil does not. In the next post I’ll discuss what else I learned from this experiment.
I can’t speak to Seth’s R program. For ours, I altered the jQuizMe plug-in by adding responseStartTime and responseEndTime variables. I bookended them on the tightest path I could find within the plugin. Certainly there is a bit of intervening plug-in plumbing, but I don’t believe it’s adding any sort of interesting lag. (The modified JS is at https://s3.amazonaws.com/genomera/instruments/math/scripts/jquery.quiz.jsif anyone wants to have a read through particularly poorly crafted javascript. You can search for anything I added by “[jtz]”.)
”’
We have used this as place to host questions and answers about Butter Mind and the math test used for it.
– Questions were designed to have only single-digit answers [0-9], and
– Questions automatically advanced after a single keystroke, whether number, letter, or symbol. Any incorrect stroke was called wrong and tossed out. The only bug I saw here was the one I mentioned – when, if two keys are hit simultaneously, the question does not advance (even though the answer is clearly wrong), but must be corrected by manual deletion then entry of a single item.
I never met you, but I’m Mel’s sister. I followed a link to your blog from an email she sent me. This is very funny that you did an experiment like this. I actually do a lot of experimenting myself with nutrition since I was a kid…although never a “real” one like this.
135 x 10
205 x 5
275x 4 x 4 (73ish% of 1 Repitition Max)
315 x 1 x 2 (86ish % of 1RM)
345 x 1 x 2 (94ish % of 1RM)
Training effect?